Вайб-обзор на GPT 5.1 / Gemini 3 Pro / Opus 4.5 (2/2)
Gemini 3 Pro
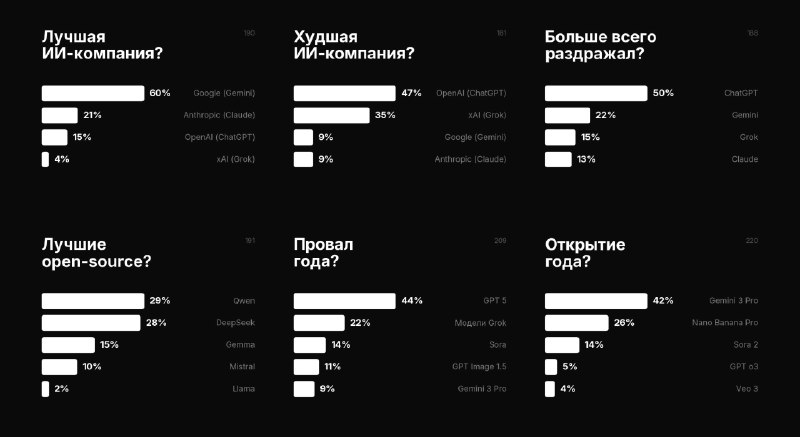
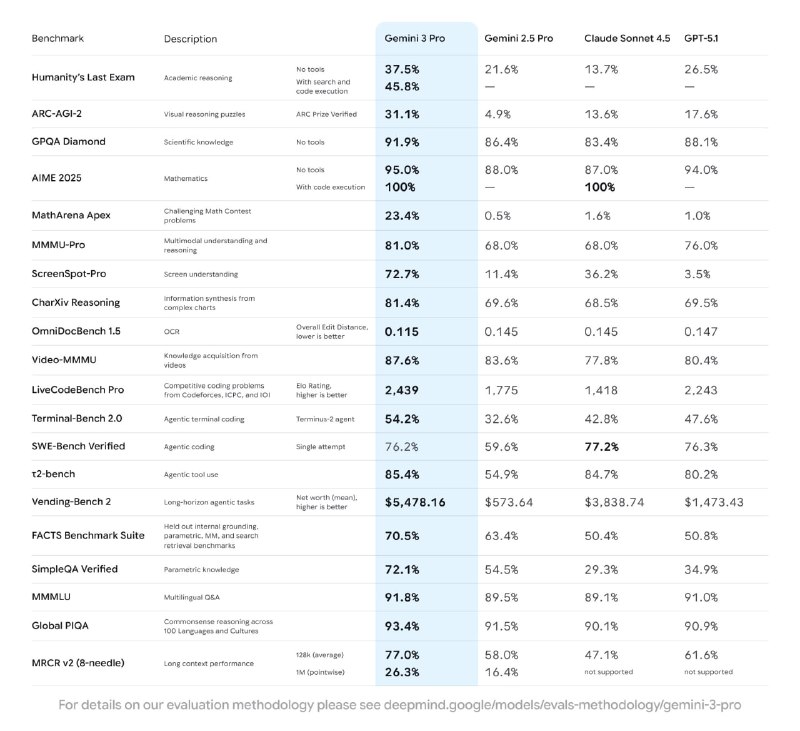
Модель перед выпуском хайпили так, что казалось, будто у всех сотрудников Google есть KPI на то, чтобы твитнуть нечто загадочное про выход то Gemini, то про что-то с цифрой 3, то про будущие фантастические возможности.
Конкретно у меня было много надежд на то, что у нас-таки будет модель уровня GPT 5, но c 1м контекста, с большей эрудицией (у GPT 5 с этим явно хуже) и агентностью.
Но чуда не случилось. Для разработки так уж точно.
Впечатление от релиза смазалось ещё и тем, что в составе продуктов, где модель стала доступной на старте, она работала довольно нестабильно (и это местами продолжается).
Ну а после того, как в реальной работе она не показала заявленного в бенчмарках, стало совсем грустно.
Нет, это безусловно отличная модель, очень начитанная, с мультимодальностью из коробки, но, кажется, её не создавали быть лучшей в разработке.
Для всего остального, впрочем, она очень хороша, а такие штуки как Nano Banana Pro и NotebookLM теперь у меня входят в набор повседневных инструментов.
Опять-таки, это Preview версия, и, возможно, тут, как и на старте GPT 5, проблема больше в тулинге, чем в самой модели, и нужно подождать месяц-другой, пока и тулинг оптимизируется, и появится новый чекпойнт модели.
А ещё стоит посматривать за прогрессом Antigravity, там есть несколько интересных задумок:
● спеки/планы как first-class citizens;
● поддержка работы с браузером через кастомное расширение для Chrome, что делает возможным модели «смотреть» на результат свой работы для замыкания feedback loop;
● отдельный интерфейс для работы с агентами;
● генерация схем проекта, дизайнов и картинок с помощью Nano Banana Pro.
Opus 4.5
Честно говоря, не думал, что Anthropic что-то сможет представить достойное на фоне прошлых двух моделей, но однако ж получилось.
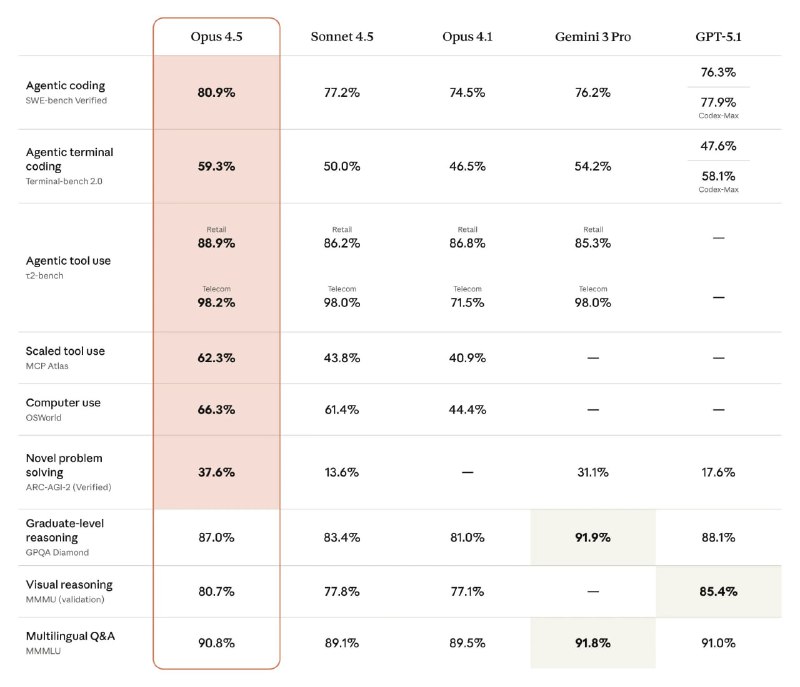
Вкупе со снижением цен это делает новый Opus приемлемым как по лимитам, так и по качеству работы.
А если добавить к этому Claude Code, который, как я уже упомянул, в принципе является лучшим CLI-агентом на текущий момент, то вообще хорошо.
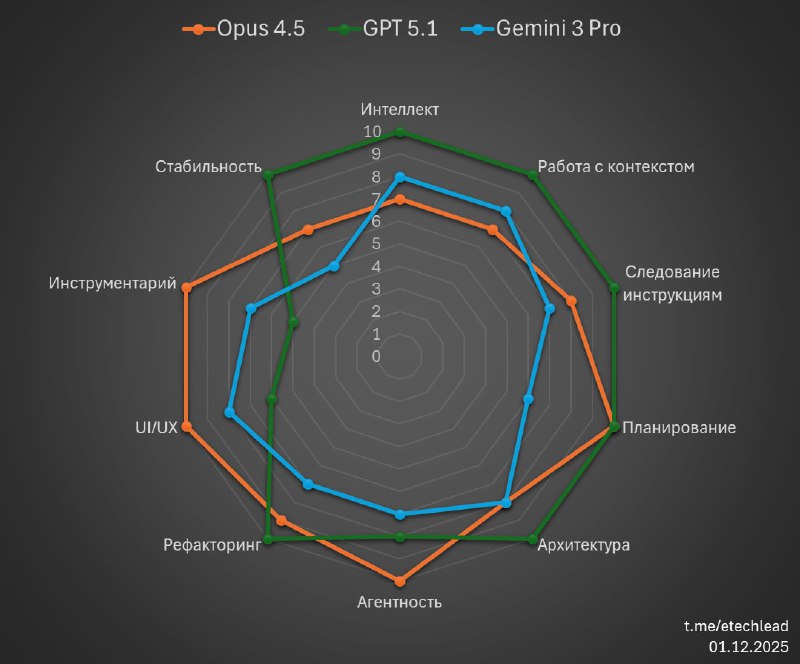
Виден рост по всем метрикам, связанным с разработкой, модель стала более аккуратной в суждениях, реже считает ваши решения гениальными и тратит меньше токенов.
Однако это всё ещё типичная Claude — стремительно улетающий контекст, недостаток внимания к мелочам, объявление нетронутых задач выполненными и т.п.
Да, всего этого стало меньше, но на это всё равно намного чаще натыкаешься, чем в той же GPT 5.1, и для эффективной работы всё ещё нужно построение более сложного набора костылей поддерживающего workflow.
Зато Claude Code + Opus — отличная связка для:
● greenfield-проектов и не очень сложных и больших проектов в целом, как для планирования, так и написания кода;
● всего, что связано с красивостями в UI;
● для агентных в целом и devops-задач в частности, когда нужно много всяких разных тулов подёргать, и через много шагов прийти к конечному результату (пока контекст не кончился, хехе).
Вердикт
Ультимативного инструмента нет, и нельзя его выбрать по какой-то одной характеристике, но если брать самые их яркие особенности, то я бы распределил их так:
● Сложный проект, много существующего кода, нужно внесение аккуратных правок, продумывая архитектуру и обсуждая варианты решения в деталях — GPT 5.1.
● Более-менее универсальная рабочая лошадка, которую вполне можно использовать как единственный инструмент, но с условием того, что вам придётся её объездить — Opus 4.5.
(прошу винить в обилии «лошадиных» аналогий модный сейчас термин harness).
● Если вам не так важна собственно разработка, а нужна вторая модель с хорошей эрудицией и интуицией не только в технических доменах, большим контекстом, хорошей мультимодальностью, а также для прототипов и ваншотов — Gemini 3 Pro.
Но в целом это, конечно, отличные обновления, прогресс весьма заметен.
И посмотрим, изменится ли что-то ещё до конца года 🙂
#ai #model #review