Вайб-обзор на GPT 5.1 / Gemini 3 Pro / Opus 4.5 (1/2)
Даа, ноябрь выдался весьма урожайным на новые модели.
Перебивая один другого, ведущие вендоры выпустили по флагманской модели (некоторые даже по нескольку).
Провел с каждой из них достаточно времени, чтобы теперь поделиться мнением 🙂
Будем считать это вайб-обзором, т.к. формальных метрик у меня нету, и по сути это набор личных впечатлений, полученных в процессе решения реальных задач.
Если не указано иного, то я рассматриваю модели чисто с точки зрения использования их для разработки и исключительно в «родных», вендорских инструментах и на платных подписках.
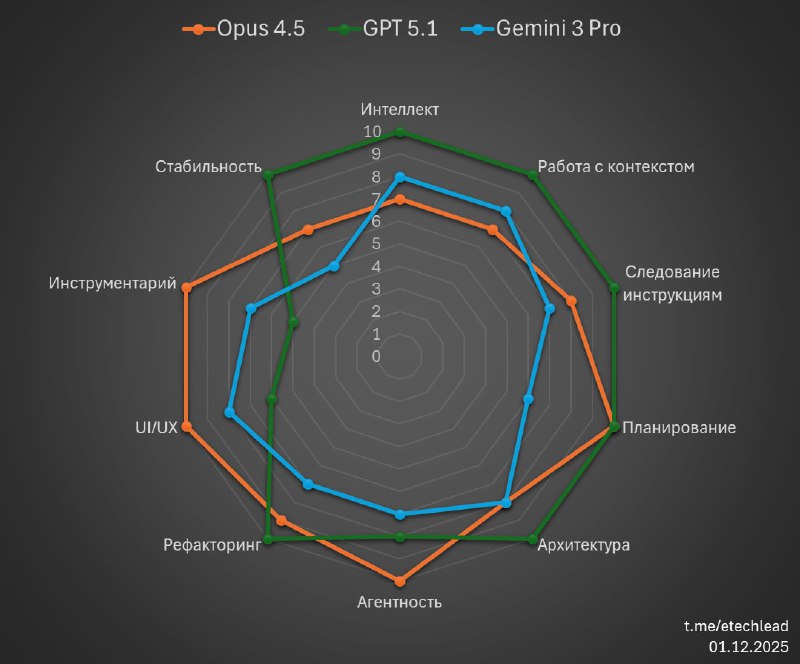
Оценки по каждой характеристике относительны и выставлены в сравнении с лучшей моделью из трёх (т.е. 10 ≠ абсолют).
Критерии
● Интеллект
В данном случае — способность к решению сложных проблем.● Работа с контекстом
Удержание, экономность использования, галлюцинации.● Следование инструкциям
… плюс способность их помнить и принимать во внимание все разом, внимание к деталям.● Планирование
Анализ требований и их осуществимости с граундингом на существующий проект, разбивка по этапам и задачам.● Архитектура
Способность понимать, оперировать и следовать архитектурным концепциям, предлагать неконфликтующие изменения.● Агентность
Автономное выполнение задач с эффективным использованием выданных инструментов.● Рефакторинг
Понимание типовых рефакторингов, code smells и способность делать широкие изменения в существующей кодовой базе.● UI/UX
Визуальная красота и удобство UI (в отрыве от красоты/сложности кода).● Инструментарий
Набор IDE, CLI, Web и прочих инструментов, где работает модель.● Стабильность
Как бесперебойность доступа к модели со стороны вендора, так и стабильность выдаваемого результата с т.з. качества.
GPT 5.1 High (+Codex, +Max)
Весьма педантичное семейство моделей, которым можно доверить сложные и глубокие задачи, а так же те, которые требуют внимания к деталям.
Ни Gemini 3 Pro, ни Opus 4.5, даже несмотря на результаты на бенчмарках, не смогли стать заменой GPT 5 там, где нужен мощный ризонинг.
Через неё у меня проходят финальные версии планов, архитектурных решений, ревью — и всё обязательно с граундингом на существующую кодовую базу и документацию.
Собственно именно работа в существующих больших проектах ей удаётся лучше всего — модель сама способна качественно собрать контекст, понять corner cases, адаптироваться к стилю кода и архитектурным паттернам, и в целом ведёт себя не как ковбой-кодер, который после прочтения пары файлов кидается писать код (да, Gemini?).
И пусть иногда сбор этого самого контекста и раздумья происходят мучительно долго, по мне так лучше подождать ради качественного результата вместо того, чтобы потом переделывать несколько раз и бороться с галлюцинациями или излишней самоуверенностью, как это бывает у других моделей.
Увы, насколько хороша модель, настолько же и плох тулинг вокруг неё.
Несмотря на быстрый старт, команда Codex CLI спустя короткое время то ли увязла в выбранных технологиях, то ли готовит какой-то другой продукт — иначе сложно объяснить игнор нужных и очевидных фич, которые просит сообщество.
Claude Code почти во всём лучше Codex CLI, но, видимо, нам нельзя иметь удобную оболочку (harness / упряжку) и хорошую модель в составе одного агента.
Ну и агентность у GPT 5.1 похуже, если сравнивать с Claude, даже в случае Codex-вариантов.
Хотя связка обычной GPT 5.1 как планировщика, а Codex-варианта как исполнителя вполне рабочая на большинстве задач.
Добавить комментарий