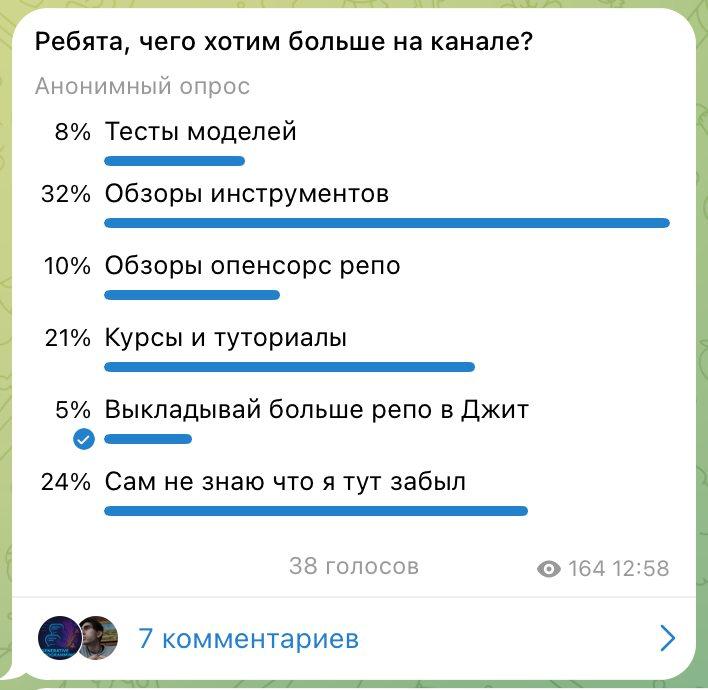
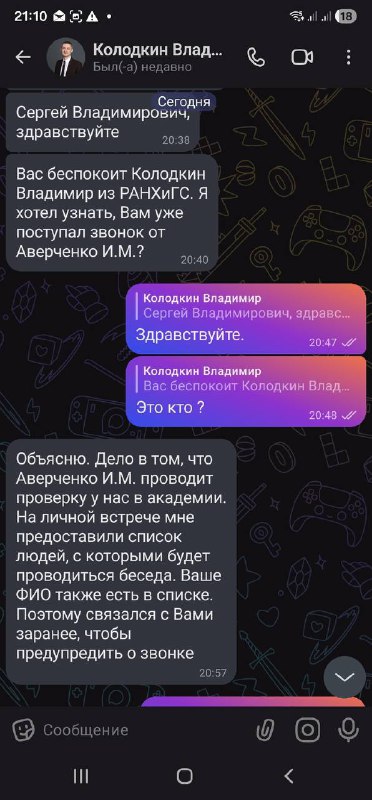
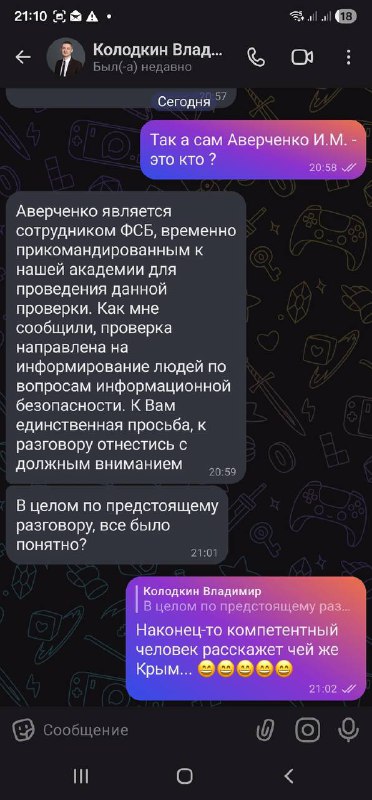
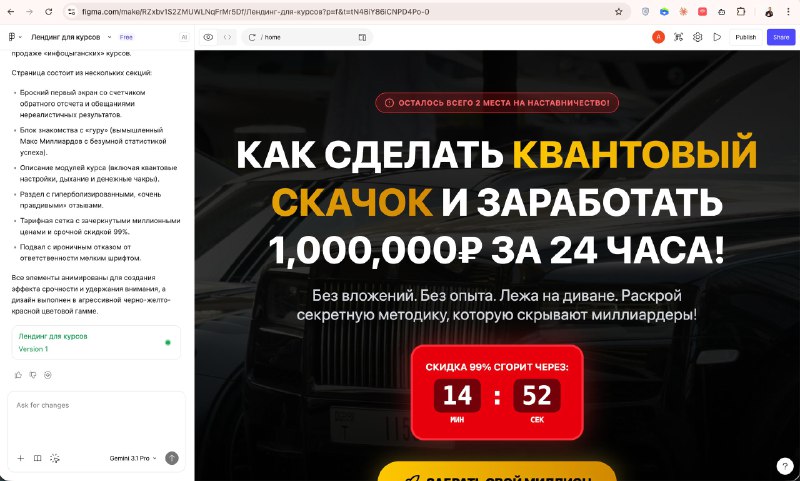
GPT-5.4, вайб-обзор
tl;dr
Очень хороша, почти универсальная модель для разработки.
Как и обещали OpenAI, ощущается как гибрид моделей:
● GPT-5.2 с её глубиной мышления и широтой знаний
● GPT-5.3 Codex с его скоростью, хорошим кодингом и агентностью
Это не такая революция как GPT-5 или 5.2, но по мелочам много всего набегает.
Что уж говорить, я почти упираюсь в лимиты Pro-плана — настолько стало интересно работать 🙂
Плюсы
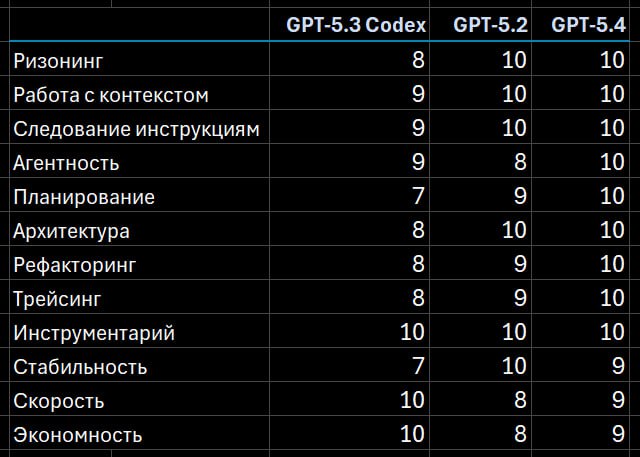
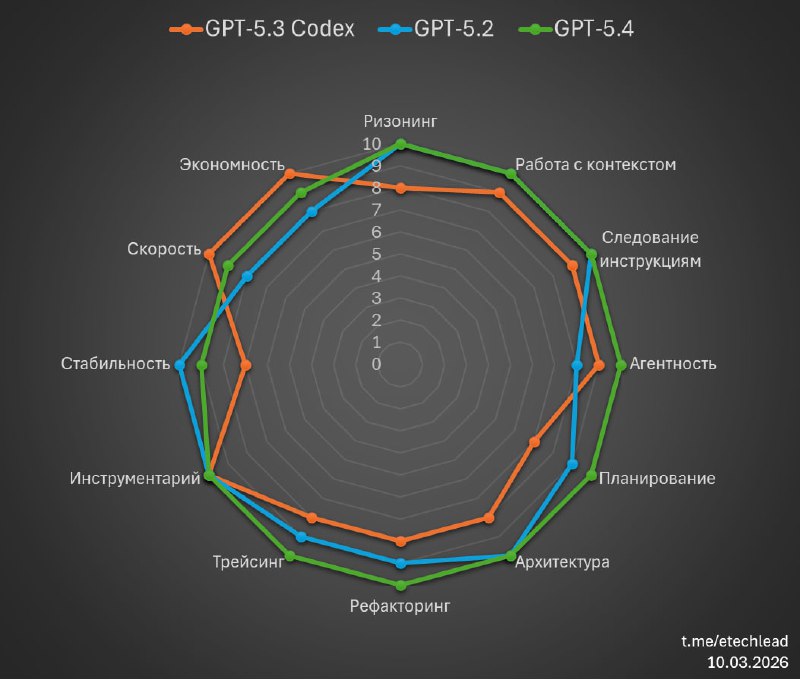
🟢 5.2 + 5.3 Codex
Не нужно выбирать модели и компенсировать недостатки одной плюсами другой.
Модель одна, и ведёт себя консистентно хорошо, достаточно лишь переключать reasoning level.
🟢 Скорость — на high работает практически со скоростью 5.3 Codex xhigh, при этом не теряя в качестве.
На xhigh ощущается шустрее, чем 5.2 xhigh.
🟢 Эрудиция — это у неё от GPT 5.2 🙂
Codex-модели, вероятнее всего, дистилляты или облегчённые тюны «полных» моделей, заточенные на код, но понимания мира у них за пределами IT не хватает.
Это делает сложным их применение в специфических предметных областях, где нужна интуиция и знания домена, а не только чистый ризонинг.
GPT-5.4 тут стала намного лучше в сравнении как с 5.3 Codex, так и даже с 5.2.
Но лидером по этому показателю, тем не менее, всё ещё остаются модели Gemini Pro.
🟢 Исследовательские способности
GPT-5.4 стала ещё лучше, чем 5.2, докапываться до багов на стыке нескольких подсистем, работать со сложными взаимозависимостями, строить длинные цепочки причинно-следственных связей, при этом устойчиво пользуясь доступными инструментами.
Недавно свою инфру менял в сторону платформы для агентов (чтобы они сами проекты devops’или), и там она весьма нетривиальные вещи творила в процессе миграции (расскажу).
🟢 Стала приятнее общаться
Не звучит так механистично как 5.2, но в довесок стала болтливее (а это у нее от GPT-5.3 Codex).
Это, конечно, вкусовщина, но вот что реально стало плюсом — она стала куда лучше писать по-русски: cтало меньше fabric, не так много details, и намного реже инвенцирует новые словs on the fly.
Блин, да она даже шутит иногда неплохо! Как будто бы тут ещё и GPT-4.5 потопталась 🙂
Минусы
🔴 Оверинжиниринг (на простых задачах)
Это было и в 5.2, но реже, а в GPT-5.4 риск того, что модель уйдёт в ненужные абстракции на xhigh, стал выше, так что стоит посматривать, что она вам предлагает.
🔴 1M контекст — Что? Как это оказалось в минусах?
Эффективный контекст GPT-5.4, судя по бенчам самих OpenAI, всё так же в районе её родных 272к токенов, а всё, что дальше — это «растягивание» внимания модели, и, как следствие, падение качества работы с контекстом, да ещё и за 1.5x+ прайс.
Этот 272к+ контекст экспериментальный, не включен по умолчанию, но я и не советую, т.к. падение качества сильно ощущается — родной контекст даже с периодическими компактизациями работает намного лучше.
🔴 UI/дизайн — всё ещё не её конёк
Но хотя бы обещались что-то с этим уже сделать в будущих релизах.
(справедливости ради, UI всё равно стоит делать в специализированных инструментах)
Особенности
⚪️ Модель предпочитает Plan-Act
5.3 Codex был более заточен на интерактивную с ним работу, где он по сути был вашим инструментом.
5.4 же больше про планирование, сбор контекста, а потом исполнение по готовому плану — тут она больше на 5.2 похожа.
⚪️ Режим /fast в агенте
Ускоряет выдачу токенов моделью в 1.5 раза, но ценой лимитов/цены 2x.
Включаю когда что-то интерактивно нужно пообсуждать/поделать, и при этом не выпадать из потока, пока модель думает.
Для исполнения средних+ планов не имеет смысла — как правило, они десятки минут и часы выполняются, и не имеет особого значения, насколько быстро инференс самой модели происходит.
Вердикт
Для использования в разработке GPT-5.4 для меня на текущий момент — SOTA.
Другие модели теперь в довольно специфических случаях используются:
● Opus 4.6 / Gemini 3.1 Pro Preview для построения UI с нуля
● GPT-5.2 xhigh изредка как второе мнение в архитектуре, планировании и контроле техдолга
Расскажите, как у вас 🙂
—
● Мои критерии оценки ИИ-агентов
● Обзор на GPT-5.3 Codex, Opus 4.6, и GPT-5.2: раз, два
#ai #model #review
GPT-5.4, вайб-обзор
tl;dr
Очень хороша, почти универсальная модель для разработки.
Как и обещали OpenAI, ощущается как гибрид моделей:
● GPT-5.2 с её глубиной мышления и широтой знаний
● GPT-5.3 Codex с его скоростью, хорошим кодингом и агентностью
Это не такая революция как GPT-5 или 5.2, но по мелочам много всего набегает.
Что уж говорить, я почти упираюсь в лимиты Pro-плана — настолько стало интересно работать 🙂
Плюсы
🟢 5.2 + 5.3 Codex
Не нужно выбирать модели и компенсировать недостатки одной плюсами другой.
Модель одна, и ведёт себя консистентно хорошо, достаточно лишь переключать reasoning level.
🟢 Скорость — на high работает практически со скоростью 5.3 Codex xhigh, при этом не теряя в качестве.
На xhigh ощущается шустрее, чем 5.2 xhigh.
🟢 Эрудиция — это у неё от GPT 5.2 🙂
Codex-модели, вероятнее всего, дистилляты или облегчённые тюны «полных» моделей, заточенные на код, но понимания мира у них за пределами IT не хватает.
Это делает сложным их применение в специфических предметных областях, где нужна интуиция и знания домена, а не только чистый ризонинг.
GPT-5.4 тут стала намного лучше в сравнении как с 5.3 Codex, так и даже с 5.2.
Но лидером по этому показателю, тем не менее, всё ещё остаются модели Gemini Pro.
🟢 Исследовательские способности
GPT-5.4 стала ещё лучше, чем 5.2, докапываться до багов на стыке нескольких подсистем, работать со сложными взаимозависимостями, строить длинные цепочки причинно-следственных связей, при этом устойчиво пользуясь доступными инструментами.
Недавно свою инфру менял в сторону платформы для агентов (чтобы они сами проекты devops’или), и там она весьма нетривиальные вещи творила в процессе миграции (расскажу).
🟢 Стала приятнее общаться
Не звучит так механистично как 5.2, но в довесок стала болтливее (а это у нее от GPT-5.3 Codex).
Это, конечно, вкусовщина, но вот что реально стало плюсом — она стала куда лучше писать по-русски: cтало меньше fabric, не так много details, и намного реже инвенцирует новые словs on the fly.
Блин, да она даже шутит иногда неплохо! Как будто бы тут ещё и GPT-4.5 потопталась 🙂
Минусы
🔴 Оверинжиниринг (на простых задачах)
Это было и в 5.2, но реже, а в GPT-5.4 риск того, что модель уйдёт в ненужные абстракции на xhigh, стал выше, так что стоит посматривать, что она вам предлагает.
🔴 1M контекст — Что? Как это оказалось в минусах?
Эффективный контекст GPT-5.4, судя по бенчам самих OpenAI, всё так же в районе её родных 272к токенов, а всё, что дальше — это «растягивание» внимания модели, и, как следствие, падение качества работы с контекстом, да ещё и за 1.5x+ прайс.
Этот 272к+ контекст экспериментальный, не включен по умолчанию, но я и не советую, т.к. падение качества сильно ощущается — родной контекст даже с периодическими компактизациями работает намного лучше.
🔴 UI/дизайн — всё ещё не её конёк
Но хотя бы обещались что-то с этим уже сделать в будущих релизах.
(справедливости ради, UI всё равно стоит делать в специализированных инструментах)
Особенности
⚪️ Модель предпочитает Plan-Act
5.3 Codex был более заточен на интерактивную с ним работу, где он по сути был вашим инструментом.
5.4 же больше про планирование, сбор контекста, а потом исполнение по готовому плану — тут она больше на 5.2 похожа.
⚪️ Режим /fast в агенте
Ускоряет выдачу токенов моделью в 1.5 раза, но ценой лимитов/цены 2x.
Включаю когда что-то интерактивно нужно пообсуждать/поделать, и при этом не выпадать из потока, пока модель думает.
Для исполнения средних+ планов не имеет смысла — как правило, они десятки минут и часы выполняются, и не имеет особого значения, насколько быстро инференс самой модели происходит.
Вердикт
Для использования в разработке GPT-5.4 для меня на текущий момент — SOTA.
Другие модели теперь в довольно специфических случаях используются:
● Opus 4.6 / Gemini 3.1 Pro Preview для построения UI с нуля
● GPT-5.2 xhigh изредка как второе мнение в архитектуре, планировании и контроле техдолга
Расскажите, как у вас 🙂
—
● Мои критерии оценки ИИ-агентов
● Обзор на GPT-5.3 Codex, Opus 4.6, и GPT-5.2: раз, два
#ai #model #review