✴️ Google DeepMind выпустила мультимодальную модель Gemini Embedding 2
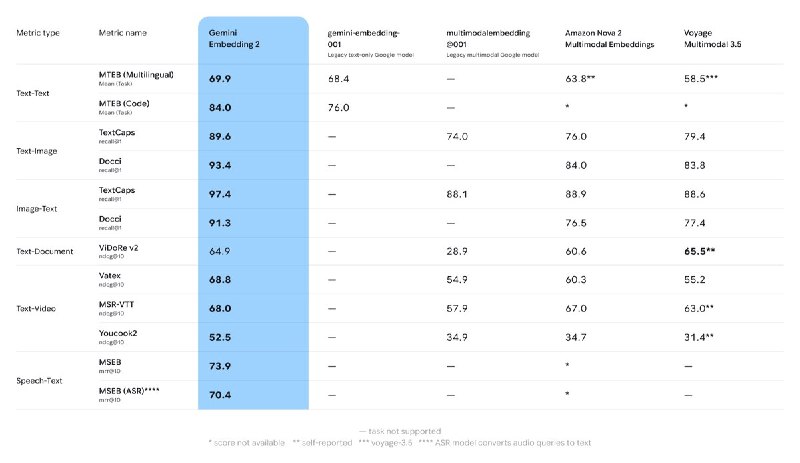
Google DeepMind представила Gemini Embedding 2. Модель переводит текст, изображения, видео, аудио и документы в единое пространство эмбеддингов. Распознает семантику на более чем 100 языках.
Для тех кто не знает, embedding модели это алгоритм, выполняющий роль универсального переводчика. Он преобразует любую информацию в многомерный числовой код (вектор). Модель нужна для того, чтобы компьютер мог анализировать, сравнивать и искать данные не по их формату или совпадению символов, а исключительно по их внутреннему смыслу и контексту.
— Обрабатывает текст с контекстом до 8192 токенов.
— Принимает до 6 изображений за один запрос в форматах PNG и JPEG.
— Анализирует видеоролики длиной до 120 секунд в форматах MP4 и MOV.
— Нативно встраивает аудиоданные без промежуточной транскрибации в текст.
— Напрямую работает с PDF-документами объемом до 6 страниц.
— Понимает смешанный ввод данных (одновременная передача изображений, текста и аудио в одном запросе).
— Масштабирует размерность вывода за счет Matryoshka Representation Learning. Базовое значение — 3072, для баланса производительности и памяти рекомендованы 1536 и 768.
Доступно в Public Preview через Gemini API и Vertex AI. Поддерживает интеграцию с LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, ChromaDB и Vector Search.
Добавить комментарий