📉 Крах контекста у Gemini-3-pro и GLM-4.7
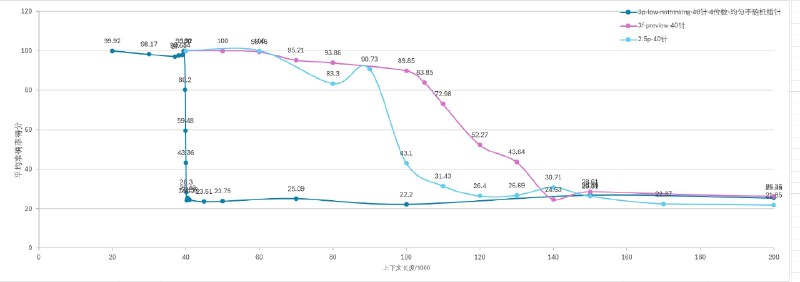
Независимые тесты «Needle In A Haystack» выявили критические ограничения эффективного контекста у моделей Gemini-3-pro и GLM-4.7, что делает их практически непригодными для использования в сложных AI-агентах.
— Gemini-3-pro: Реальное эффективное окно ограничено ~40 КБ. На отметке 40.3 КБ точность начинает падать, а к 40.6 КБ происходит резкий обрыв до 28.3%. Далее ответы становятся случайными.
— GLM-4.7: Стабильно работает только до 35K (при заявленных 200K). На 40K успешность падает до 55%, а на 50K наступает полный отказ (0% успеха).
— Инструменты вроде Claude Code или OpenCode занимают 20–23K системного промпта на старте.
— Пользователю остается всего ~15K полезного окна, чего абсолютно недостаточно для работы с кодом.
При выходе за эти лимиты модели теряют логическую нить и начинают отвечать невпопад.


Добавить комментарий