На чем строится SPLADE и bge-m3 sparse vector и почему это совсем не полнотекстовый поиск.
Потихоньку возвращается рубрика разборов, тем более, жду техрепорт DeepSeek v4.
Сегодня расскажу про sparse, который не совсем sparse, и вовсе не bm25/tfidf.
Откуда ноги растут, 📦?
Да вот, давече, читал очередной пост про hybrid rag, думаю, дай гляну, мб че новое есть. И вижу, что люди пишут: берём dense поиск с bge, а далее полнотекст от него же в виде sparse. И тут меня повело. 🌟 Думаю, че там завезли за полнотекст в bge? Открываем мы оригинальную статью.
А там... Нет никакого полнотекста!🚬
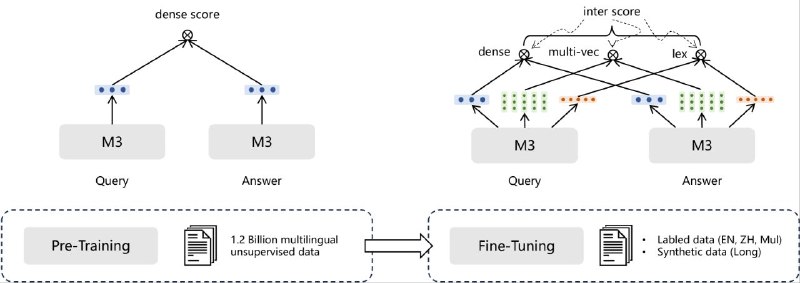
Sparse вектора учатся в той же тушке трансформера bge, через два слоя отображения. На вход модели, когда приходит токен, он получает плотный вектор эмбеддинга h. Далее его отображают через linear в пространство w размерности словаря токенайзера (скок токенов в словаре). Потом, после функции ReLU(w), мы получаем значения этого вектора в каждой компоненте >=0.
Т.е. следим за пальцами, bm25 или tfidf используют прям потокенное кодирование частотами, к примеру, есть в тексте токен из словаря 1, нет 0 (эт бинарное кодирование), или его частота встречаемости.
В sparse bge-m3 мы все ещё используем трансформер +2 новых отображения, это все ещё семантический вектор, попоржденный из плотного. И этот вектор не кодирует наличие токена или отсутствие в документе. А что он кодирует? Он делает отображение вашего вектора на пространство токенов, те по сути учится отображать, как этот токен взаимосвязан в разреженном пространстве с другими. Для примера вспомните SVD разложение для рекомендаций там мы отображаем пространство юзеров к фильмам. Однако вектор токена все ещё семантический, хоть и sparse. Это легко понять по способу обучения этой модели. Мы решаем все ту же задачу, обучаем сетку сведению текстов запроса и релевантных ответов, и разведения с нерелевантными, bm25/tfidf такого нет, мы там ничего не учим. Только для sparse голова использует близость в виде скалярного произведения. Это позволяет для ненулевых общих позиций векторов документов просто иметь попарно их произведение. Также, мы не работаем на уровне токенов, а работаем на уровне документов. А вектор документа из таких токенов получается не средним mean pool из них, а через max pool. Это позволяет выделять максимальные компоненты по позиции в векторах токенов, а не размывать их. В качестве функции ошибки между вектором запроса и ответа используется infoNCE просто вместо косинуса, там скалярное произведение. Далее присыпаются самовыравниванием на другие dense головы — берут к ним оценку корреляции в виде КLD или MSE. Учат так сказать быть в синке 😉
При этом, чтобы после таких операций вектор все ещё при обучении не выродился в плотный, его специально штрафуют через l1 норму, как сумму модулей всех весов вектора документа. Привет l1 регуляризация. А ещё, чтобы вектора забрали свойства idf, мы штрафуем за то, что те или иные позиции векторов слишком часто встречаются в других документах батча. Это делается при помощи l2 регуляризации уже весов по батчу — мы штрафуем сумму квадратов весов векторов в батче, а не на один документ как в l1. Кстати, также учится и SPLADE.
Таким образом, мы учим семантику, просто в разреженном пространстве. Это не полнотекстовый поиск, в нем не заложен тот смысл что был в tfidf. Причем это учится на одних и тех же кандидатах, что для dense голов. Тогда почему мы получаем иных кандидатов при поиске? А дело в том, что изменили форму пространства дважды, при помощи смены векторов и функции ошибки. У нас вектор не плотный и учится он не по косинусу, а по dot prod. В плотном пространстве у нас вектора лежат, как облака точек размазанных по поверхности единичной гиперсферы. А sparse вдоль лучей разреженного (те вдоль радиусов бесконечного шара) пространства. Отсюда и артефакты появления иных кандидатов.
В общем, я все ещё советую сюда подмешивать tfidf /bm25, помимо bge dense и sparse кандидатов. Можно ещё пользоваться подходящими индексами для такого, писал тут. Ну и не называйте больше этот подход полнотекстом. Все же это не так. 👍
Добавить комментарий