
Ранние отзывы об Opus 4.7 (от тестировщиков)
Но, давайте не останавливаться на достигнутом и изучим раздел Testing Claude Opus 4.7», там карусель из 28 отзывов.
HEX
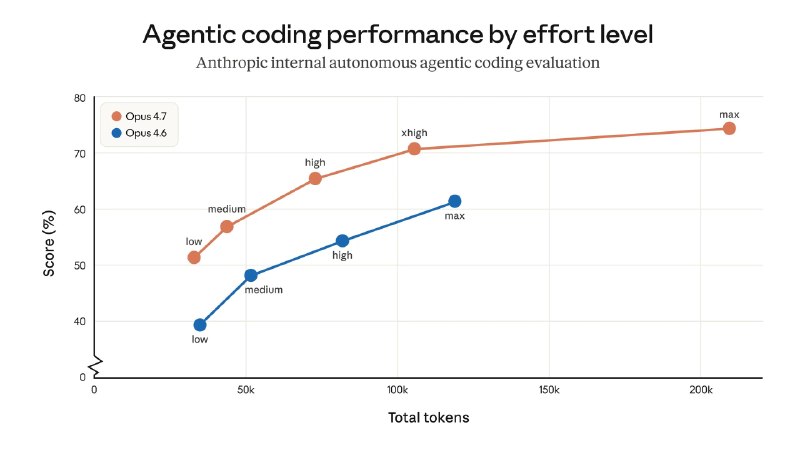
Это более интеллектуальная и эффективная версия Opus 4.6: Opus 4.7, требующая меньших усилий, примерно эквивалентна Opus 4.6, требующей средних усилий.
GitHub
В нашем тесте на 93 задачи Claude Opus 4.7 повысил разрешение на 13% по сравнению с Opus 4.6, включая четыре задачи, которые не смогли решить ни Opus 4.6, ни Sonnet 4.6.
И далее идет график на котором max 4.7 жрёт 200k+, а не 120k как у 4.6
Это почти в 2 раза больше токенов на одном запуске.
Но ключевой момент — не per-attempt, а per-success
График показывает один запуск на задачу, а не «токены до правильного ответа». Вопрос был именно про retry-экономику.
То есть Hex не зря сказал «low-4.7 ≈ medium-4.6» — график это подтверждает один в один, и даёт выигрыш даже без учёта ретраев.
График не противоречит тезису об экономии, но сужает его границы: экономия есть при сравнении «за одинаковое качество» и при сравнении одинаковых уровней усилий. Если сравнивать max против max — 4.7 действительно дороже в пересчёте на одну попытку, и оправдать это можно только если прирост качества (+13 процентных пунктов) для вас критичен. В документации Anthropic прямо предупреждают: max склонен к избыточным рассуждениям, используйте его только когда замеры показывают, что на xhigh ещё есть запас для роста.
Практический вывод: не поднимайте уровень усилий «на всякий случай» — для большинства задач high или xhigh на 4.7 это золотая середина, которая одновременно и дешевле, и лучше соответствующих уровней 4.6.
Добавить комментарий