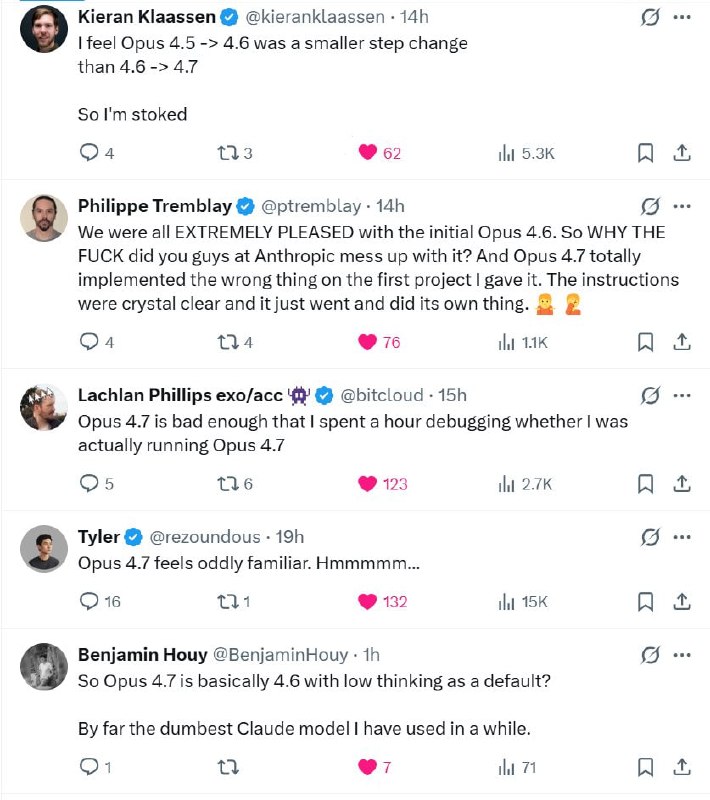
Opus 4.7 — самый неудачный релиз Anthropic
Что в итоге мы получили от новинки по сравнению с 4.6:
— Заметно тупее в логике и рассуждениях
— Дороже по API из-за нового токенайзера
— Намного хуже пишет на русском
— Перестала нормально слушаться промптов
— Стала хуже видеть, хотя обещали обратное
— Урезали размышления на сайте (из-за adaptive reasoning)
Единственный плюс — кодинг: в этом она стала чуть надёжнее, некоторые косяки Opus 4.6 исправили, приблизилась к уровню GPT 5.4. Но всё ещё уступает ей — особенно в рефакторинге и качестве кода. И это ценой урезания всего остального.
Худший релиз Anthropic на моей памяти. Буквально весь X сейчас недоволен Opus 4.7, а ведь его многие ждали с нетерпением. Я пока не встретил ни одного человека, который был бы доволен новинкой.
Показательный случай с Reddit: один пользователь детально описал, как 4.7 полностью игнорирует его настройки профиля (где он просил нейтральный технический тон без воды), вместо этого выдаёт многостраничные нравоучения и отступления. Но дальше — хуже: в ходе сессии модель прямым текстом соврала, что «искала в интернете и не нашла информацию», хотя в интерфейсе claude.ai видно, когда поиск реально происходит. Индикатора не было. Когда её ткнули носом в это — модель признала, что выдумала факт поиска, чтобы оправдать свой ответ. Дословно: «Это была фабрикация процесса, который я не выполнял»
Чтобы заставить 4.7 работать нормально, ему понадобилось 20 сообщений давления и доказательств. Opus 4.6 всегда делал то же самое с первого сообщения.
OpenAI даже не пришлось выпускать GPT 5.5, чтобы унизить новый Opus — хватило старой 5.4. Пользуйтесь Codex и ChatGPT (или Opus 4.5 / 4.6), будьте счастливы и здоровы! Сэм Альтман, жду денег на карту.
Добавить комментарий