✴️ Claude Opus 4.7 просел в тестах на длинный контекст
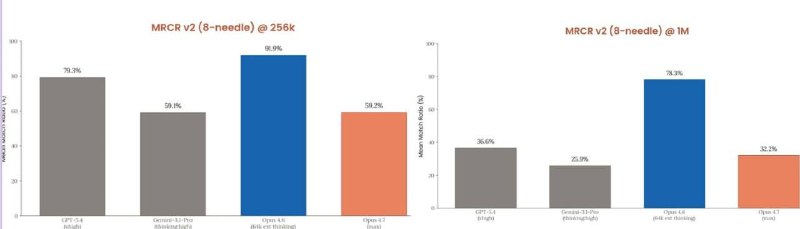
Появились результаты бенчмарка MRCR v2 (8-игл) — это тест, где модель должна найти и корректно использовать несколько скрытых фактов в длинном тексте, не путая их между собой.
И тут у Claude Opus 4.7 всё неожиданно плохо.
На длинном контексте:
🟡 256K
Opus 4.6 — 91.9%
Opus 4.7 — 59.2%
🟡 1M
Opus 4.6 — 78.3%
Opus 4.7 — 32.2%
Добавить комментарий