🧠 Вышел ARC-AGI-3
Франсуа Шолле представил интерактивный бенчмарк ARC-AGI-3 для измерения интеллекта ИИ-агентов. Он оценивает способность обучаться на лету и адаптироваться к новым задачам без предварительных знаний.
— Заменяет статические головоломки на интерактивные видеоигровые grid-среды. Агент исследует мир, открывает цели и строит модель окружения через пробы и ошибки.
— Работает без естественного языка, инструкций, подсказок и культурного контекста. Опирается исключительно на базовую логику: объектную перманентность, причинность и пространственные отношения.
— Считает эффективность приобретения навыков по количеству действий агента до достижения результата в сравнении с человеком.
— Включает более 1000 уровней в 150 созданных вручную окружениях. Поддерживает запись повторов для детального анализа логики решений.
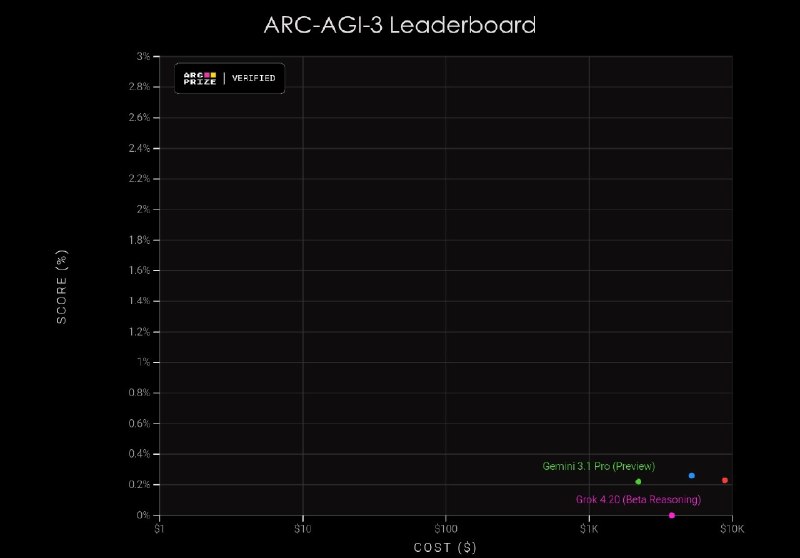
— Фиксирует тотальный разрыв: люди решают 100% задач за минуты, тогда как лучшие модели не справляются:Gemini 3.1 Pro набирает 0.37% GPT-5.4 — 0.26%
Claude Opus 4.6 — 0.25%
Grok-4.20 — 0%
Доступно в веб-версии и через Python-пакет arc-agi. Код опубликован на GitHub, а статистика собирается в открытом лидерборде.
Добавить комментарий