✴️ Google показали TurboQuant — квантование без потери качества
Google представили TurboQuant — новый подход к квантованию, который может сильно изменить эффективность LLM. Суть в том, что проблема современных моделей — не только в параметрах, а в огромных объёмах векторов (KV-cache, RAG), которые тормозят инференс и съедают память.
Подробнее:
разбор от Google
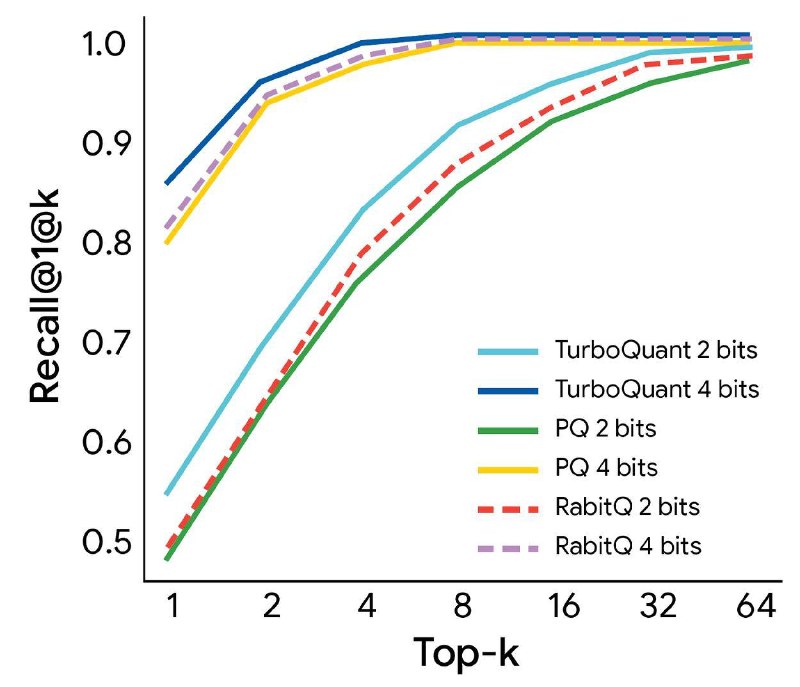
Обычно квантование просто грубо округляет числа, из-за чего падает качество. TurboQuant делает это умнее, стараясь сохранить смысл данных при сильном сжатии.
Как это работает
Метод состоит из двух частей:
🟡 PolarQuant — сначала «поворачивает» вектор так, чтобы его можно было сжать с минимальными потерями
🟡 QJL (Quantized Johnson-Lindenstrauss) — добавляет дешёвую коррекцию ошибки (буквально +1 бит на компоненту), чтобы восстановить точность
Вместе это даёт сильное сжатие без заметной деградации.
Что это даёт на практике
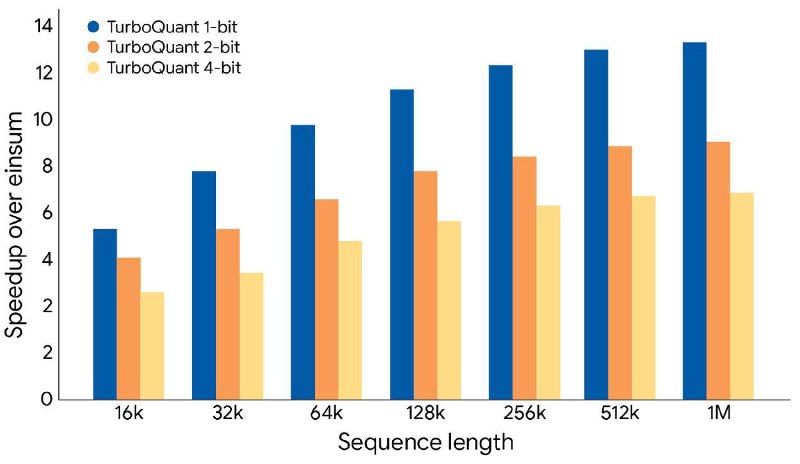
🟡 длинный контекст становится дешевле
🟡 инференс на том же железе — быстрее
🟡 RAG и vector search — компактнее и эффективнее
В экспериментах:
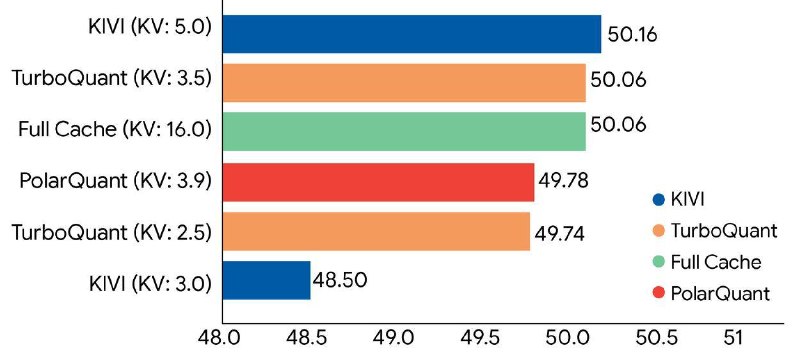
🟡 KV-cache удалось сжать до ~3 бит
🟡 без дообучения
🟡 почти без потери качества
Причём результаты близки к теоретическому пределу эффективности.
Это не просто оптимизация, а инфраструктурный апгрейд:
чем дешевле память и быстрее доступ к векторам → тем масштабнее и быстрее становятся агентные системы и long-context модели
Если технология пойдёт в продакшн, это может стать новым стандартом для LLM-инференса.
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
Добавить комментарий