
📛 Attention Residuals — новая архитектура для эффективного масштабирования нейросетей
Исследователи из Moonshot AI представили новый подход к архитектуре нейросетей — Attention Residuals (AttnRes). Он предлагает заменить классические residual-соединения на механизм внимания между слоями, где модель сама решает, какие представления из предыдущих слоёв использовать.
В традиционных трансформерах residual connections работают по фиксированной схеме: каждый слой просто добавляет свой результат к предыдущему состоянию. В Attention Residuals вместо этого используется обучаемое внимание к предыдущим слоям, что позволяет сети выбирать наиболее полезные представления из глубины модели.
Основные идеи метода:
🟡 сеть может выборочно обращаться к представлениям из предыдущих слоёв
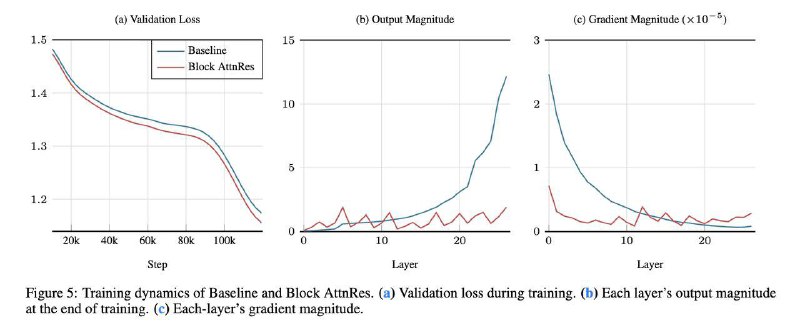
🟡 уменьшается эффект размывания информации и роста hidden-state
🟡 появляется более равномерное распределение градиентов по глубине сети
Чтобы сделать такой механизм масштабируемым, исследователи предложили Block AttnRes — архитектуру, где слои объединяются в сжатые блоки, между которыми применяется attention. Это снижает вычислительные затраты и делает cross-layer внимание практичным для больших моделей.
Метод протестировали на архитектуре Kimi Linear (48B параметров, 3B активных). Эксперименты показали:
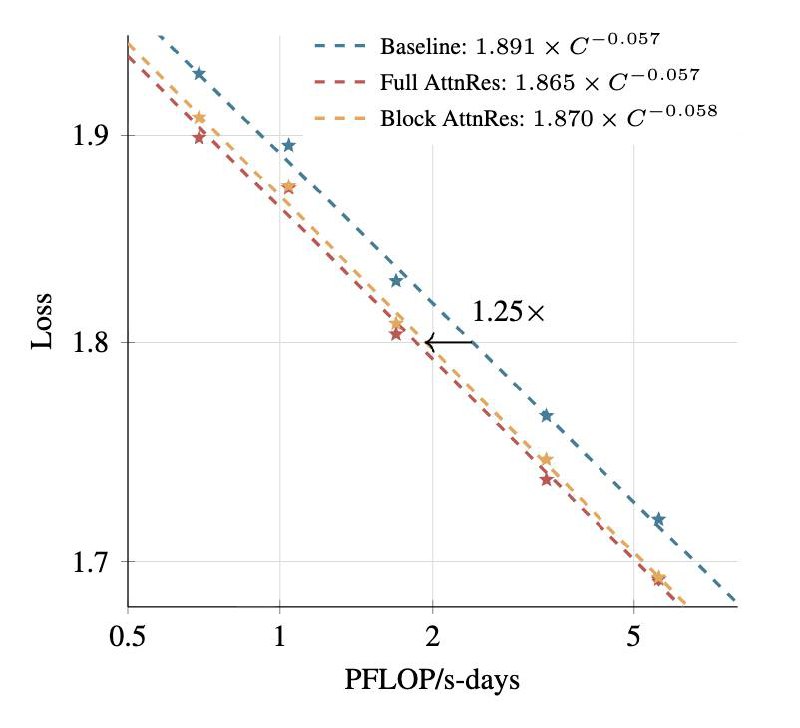
🟡 примерно 1.25× преимущество по вычислительной эффективности
🟡 менее 2% дополнительной задержки инференса
🟡 стабильное улучшение качества на downstream-задачах
Scaling-эксперименты также показали, что выигрыш в вычислениях сохраняется при увеличении размера модели.
Проще говоря, вместо того чтобы тащить через всю сеть одинаковый «след» вычислений, модель сама выбирает, к каким прошлым представлениям ей лучше вернуться, если они полезны для текущего шага. Это делает обучение стабильнее, уменьшает потерю информации в глубине сети и позволяет моделям работать примерно на 25% эффективнее по вычислениям.
Подробности можно посмотреть в исследовательской работе.
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
Добавить комментарий