Кэш в LLM API. Один параметр, который может изменить всю экономику inference.
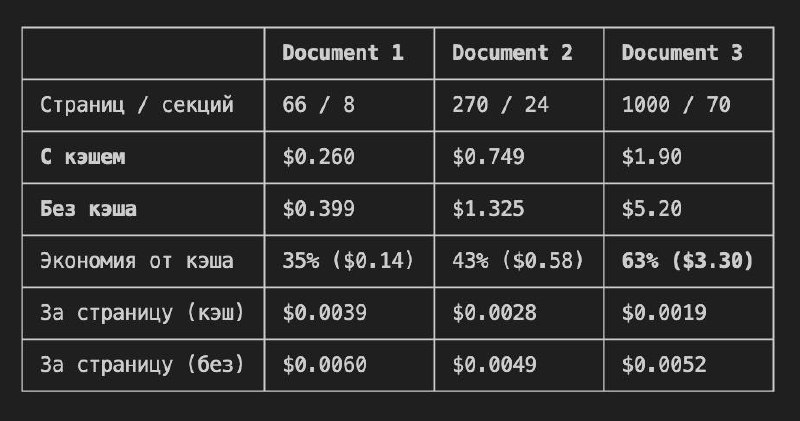
На скрине сводка из эксперимента в одном из последних проектов, где используется Anthropic API, в котором кстати кэш не включен по дефолту.
Собирался написать пост об этом, но наткнулся на разбор, который сделал это лучше. Сергей Нотевский написал подробную статью про экономику кэширования у разных провайдеров.
В статье, помимо прочего:
• почему два одинаковых запроса могут отличаться в цене в 3 раза
• какие паттерны в промптинге незаметно убивают кэш
• чем отличаются контракты кэширования у OpenAI, Anthropic и Gemini и почему миграция между ними роняет hit rate вдвое
• как команда Manus снизила стоимость инференса в 10 раз тремя простыми практиками
• почему Gemini Flash-Lite с кэшем оказывается дешевле DeepSeek в ~2.7 раза
У Сергея вообще отличный канал, рекомендую подписаться @sergeinotevskii, там много практических постов, особенно на тему локальных LLM и есть другие разборы, например про проблемы большого контекстного окна. Так что воспользуюсь моментом и рекомендую канал Сергея)
Добавить комментарий