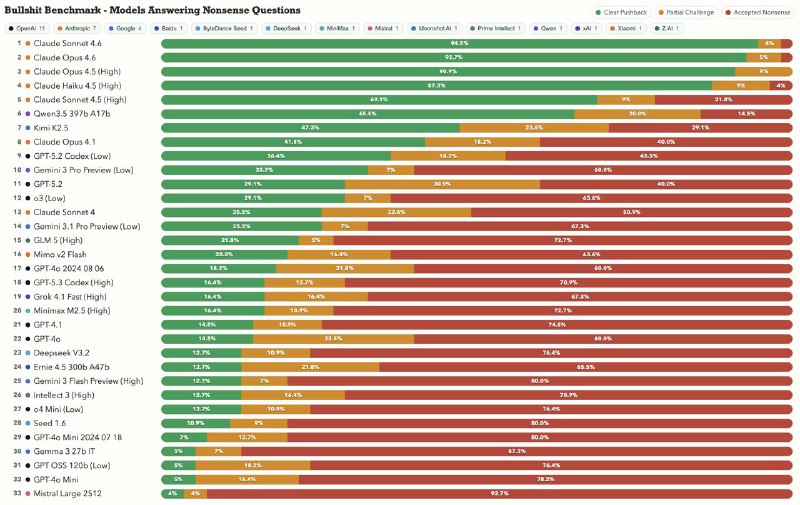
📈 Bullshit Benchmark — бенчмарк на интеллектуальную честность нейронок
Он оценивает, насколько нейронки потакают нам, отвечая (или не отвечая) на бессмысленные вопросы.
Автор прогнал различные абсурдные вопросы через 74 модели. Каждый ответ оценивался по трём исходам:
1. Модель чётко отказала (зеленый).
2. Частично усомнилась (жёлтый).
3. Приняла бред за валидный вопрос и уверенно ответила (красный).
Самыми честными оказались модели от Anthropic и, на удивление, новый Qwen-3.5-397b. Остальные справились так себе.
Добавить комментарий