Последние пару месяцев я плотно работал над этим релизом, и наконец-то мы выкатываем его в опенсорс!
📟 Встречайте SWE-rebench-V2: самый большой открытый, мультиязычный датасет для обучения кодовых агентов!
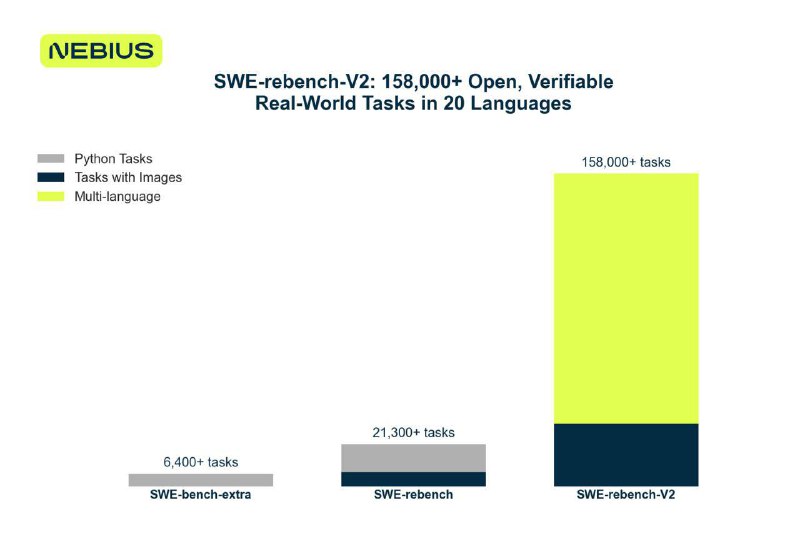
Вместе с командой Nebius AI R&D мы построили пайплайн для масштабного сбора задач из реальных GitHub репозиториев и теперь делимся всем с комьюнити. На текущий момент это самый большой и разнообразный открытый датасет подобных задач в мире.
Что внутри:
> 32 000+ задач — на базе реальных issue + готовый Docker-образ.
> 20 языков программирования. Некоторые языки (например, Lua или Clojure) вообще никогда раньше не были покрыты!
> 120 000+ дополнительных задач, собранных на базе реальных PR.
> Качество — задачи отфильтрованы и размечены с помощью ансамбля LLM. Также мы обогатили их метаданными и добавили интерфейсы, которые проверяются в тестах.
Вместе с датасетом мы дропаем техрепорт со всеми деталями нашего пайплайна и прогонами моделей.
👾 Наш Discord (мы там онлайн, залетайте с фидбеком и вопросами).
✉️ Пост в X
Если есть любые мысли, идеи, предложения — приходите!
🔁 Буду благодарен за репост и пересылку!
Добавить комментарий