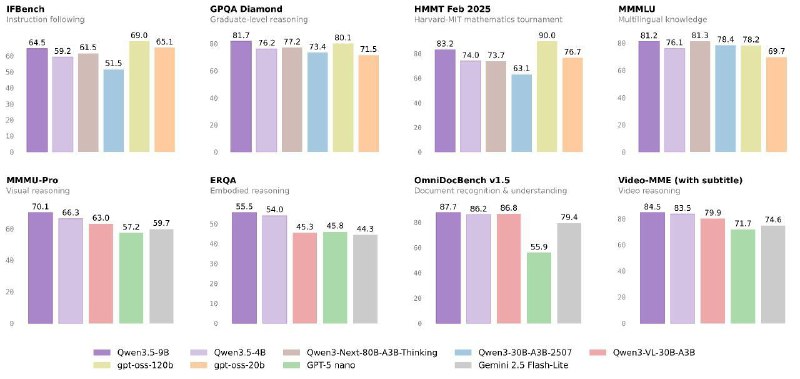
Coming soon😜 Upd. 2-4b на агентов и тулколл с MemAgent, 0.8b-4b на эмбы 💪Тут кстати выдался скорый повод для рубрики #ИИзнанка про метрики LLM на примере легких моделей Qwen 3.5. Модели, кстати, таки вышли в открытый доступ и можно найти их в HF.
Ребята в соседних чатах интересуются, как так 9b лучше по тестам 80B из семейства Qwen3? Для ответа на этот вопрос, я бы дождался техрепорта, которого в репо ещё нет – там, пока, paper не залинкован. Может, дело в развитии из гибридного внимания о котором я писал тут? Или же нативная мультимодальность – нет больше отдельных VL версий? А ещё, может, виновато расширение языковых возможностей до 201 языка? Посмотрим. 🤷♂
Но как обычно работают с метриками всякие злодеи — кратенько расскажу. Тут вариантов не так уж и много.
Самый наглый способ дотянуться до открытых тестовых сетов бенчей. Просто тупо их скачав в свой претрен или тюн. 😐 Далее, кто похитрее, аугментирует доступные публичные тестовые примеры 🧠 и уже аугментации кладёт в обучение. Можно конечно и с дистилляцией извращаться, пылесося знания сильных моделей, который тоже как бэ могли вобрать в себя публичные бенчи.
Ну и конечно путь сильных, действительно сделать что-то интересное с тюном честно, поэтому ждём репорт. А там посмотрим. 🆒
Добавить комментарий