Вайб-обзор на GPT-5.3 Codex, Opus 4.6, и (бонус) GPT-5.2 (1/2)
Тееек, потестил новые модели от OpenAI и Anthropic.
Надо сказать, что сравнивать модели становится всё нетривиальнее и дольше, потому что способности подрастают у них у всех, и отличий в качестве исполнения чисто технических задач становится всё меньше.
Ну, благо нетривиальных рабочих задач пока что хватает 🙂
tl;dr
● GPT-5.3 Codex — кодер, повседневный инструмент инженера
Шустрый, технически прошаренный, дотошный в исполнении выданных инструкций, но это именно исполнитель
● Opus 4.6 — вайб-генералист
Быстро что-то сделать с нуля, добавить не самую критичную фичу в существующий проект, но нужно держать в узде, если требуется внимательность и точные изменения
● GPT-5.2 — инженер
С ним надёжнее всего планировать, обсуждать варианты решений сложных проблем, и в целом держать проект под строгим контролем
Стандартный дисклеймер
● модели тестируются только в составе родных обвязок
● на платных подписках
● reasoning — максимальный (изредка high вместо xhigh в случае GPT)
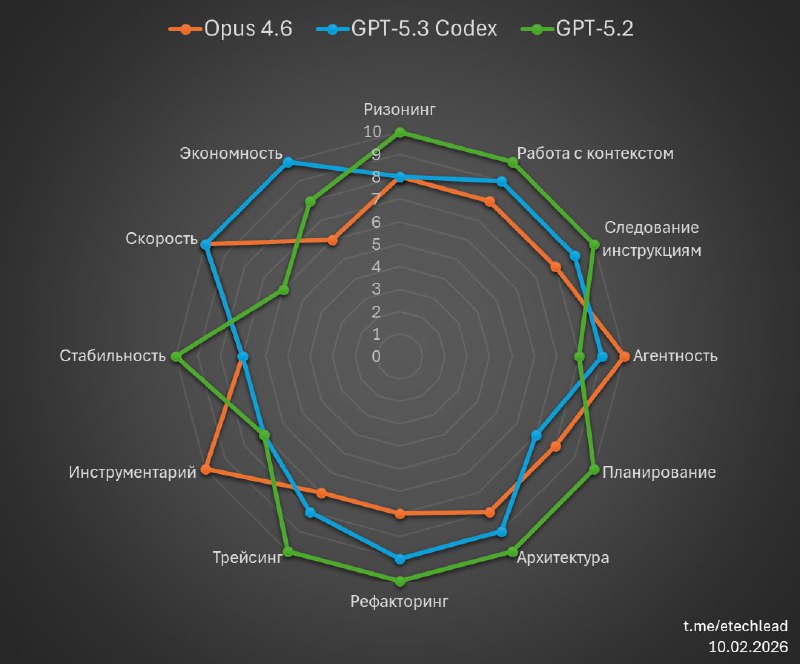
Критерии из таблицы и графика (и почему это вайб-обзор) описаны в предыдущем посте.
GPT-5.3 Codex
🟢 Скорость
Это прям главное отличие, которое сразу бросается в глаза. На практике некоторые задачи делает в разы быстрее, чем 5.2 и при этом тратит в разы же меньше токенов.
При том, что она ненамного хуже 5.2 по интеллекту, это делает её удобной в интерактивном использовании, когда вы быстро получаете результат, не выбиваясь из потока.
🟢 Болтливость
Будем считать это плюсом 🙂 Если работать с ней в интерактивном режиме, то модель теперь не сердито сопит и молча что-то делает, а активно сторителлит рассказывает, что происходит. И это удобно в сочетании с фичей Steer mode, когда мы можем добрасывать модели указания, не дожидаясь окончания её работы.
Тоже в копилку удержания себя в потоке при интерактивной работе.
🟢 Лучше делает UI/UX
Да, стало лучше, чем в семействе 5.2, но Opus 4.6 тут явный лидер.
🟡 Объем и глубина задач
Несложные и/или вширь, потому что со сложными/вглубь она скорее всего какие-то нюансы потеряет.
Скажем, дать ей какой-то простой рефакторинг типа «избавься от any в проекте» — она и сутки может с ним возиться, и таки доведёт до конца.
А вот составить полноценный план большой фичи с учётом всех деталей — как повезёт.
🟡 Дотошность исполнения
Это отличная модель-исполнитель, но ох, не стоит ей давать необдуманные задачи. Пусть она и не сделает противоречивое и неработающее решение, но ответственно будет следовать абсурдным требованиям.
Сюда же — она очень пронырливая, но её нужно об этом явно просить (в отличие от 5.2, которая старается максимум информации собрать сама).
🔴 Рандомность ризонинга
Это фишка, которая особенно заметна на Codex-семействе моделей — чем сложнее задача, тем дольше и качественнее она думает.
Точка перехода между (терпи, сова) активацией системы 1 и 2 (по Канеману) тут смещена в сторону системы 1 сильнее, чем у базовой модели.
Но со стороны это может выглядеть именно как рандомные по времени ответы, плавающие по качеству.
Этого стало меньше в сравнении с 5.2 Codex, но это всё ещё есть, хотя в прыжке модель может ризонить не хуже базовой 5.2.
Opus 4.6
🟢 Лучше держит контекст
По MRCR у неё какие-то фантастические метрики, делающие модель SOTA на этом бенче, но я этого не вижу в работе.
Да, стало ощутимо лучше в сравнении с Opus 4.5, но до GPT-5-семейства не дотягивает.
Лучше, кстати, стало, как до компактизации, так и после неё — сохраняется больше информации.
🟢 Меньше галлюцинаций и вранья
Это отчасти связано с тем, что модель лучше держит контекст, а отчасти с тем, что она чаще делает граундинг на файлы проекта, чтобы не фантазировать о нём.
🟢 Чаще стала задумываться
Кому-то может показаться, что модель просто замедлилась, но это влияет на качество на сложных задачах — там, где Opus 4.5 старался дать ответ быстрее, Opus 4.6 даёт его правильнее.
продолжение в следующем посте
Добавить комментарий