⚡️ Вышла модель GLM-4.7-Flash
Компания Z.ai представила GLM-4.7-Flash — модель класса 30B, оптимизированную для локального запуска, написания кода и агентных задач.
— Архитектура Mixture-of-Experts (MoE): всего 30B параметров, активных — 3B.
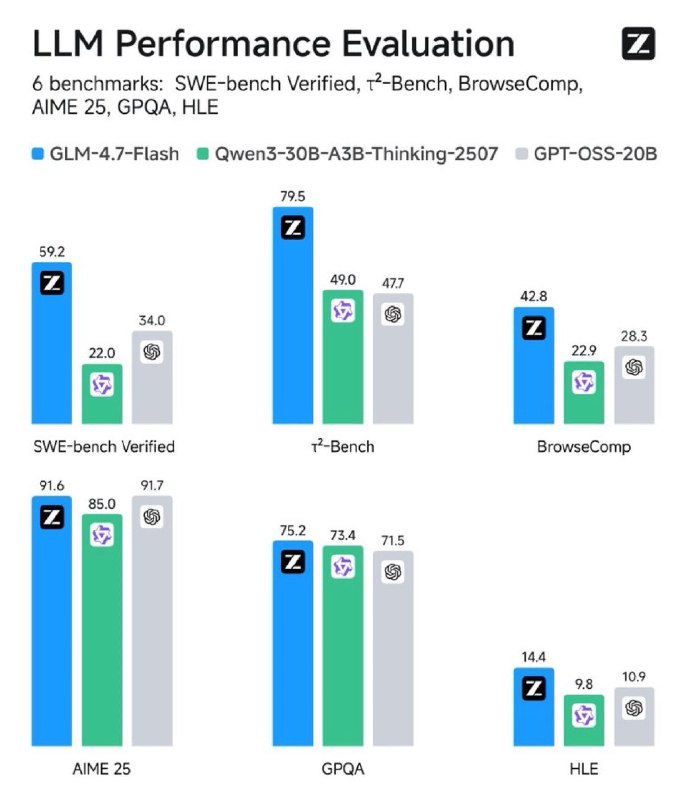
— В тесте SWE-bench Verified (кодинг) набрала 59.2%, обойдя Qwen3-30B и GPT-OSS-20B.
— Демонстрирует высокие результаты в математике (91.6% AIME 25) и веб-навигации (42.8% BrowseComp).
— Поддерживает контекст до 128K токенов и эффективный tool calling (работа с инструментами).
— Запускается на картах уровня RTX 4090 и чипах Apple M-серии (до 81 t/s).
Добавить комментарий