✴️ Opus 4.7 по мнению пользователей, ухудшили
Первые тесты сообщества показывают, что Opus 4.7 уступает версии 4.6 в логике и работе с контекстом. Модель перестала справляться с базовыми задачами, которые решает даже открытая Gemma. Anthropic убрала ручное управление рассуждениями (reasoning) — теперь режим работает адаптивно, но на практике почти не включается при обычных запросах. При этом новый токенайзер увеличил объем входящего текста в 1.35 раза, из-за чего лимиты расходуются быстрее.
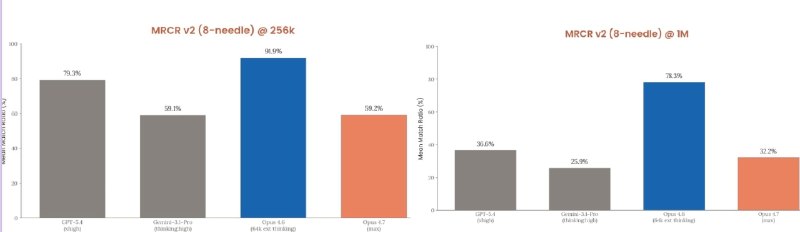
Качество работы с длинным контекстом также упало. В бенчмарке MRCR v2 на поиск скрытых фактов точность Opus 4.7 на 256K токенов составила 59.2% (против 91.9% у версии 4.6). На 1M токенов показатель снизился до 32.2%, что хуже результатов Gemini 3.1 Pro. В Claude Code принудительно включить рассуждения или откатиться на старую версию 4.6 невозможно.
Добавить комментарий