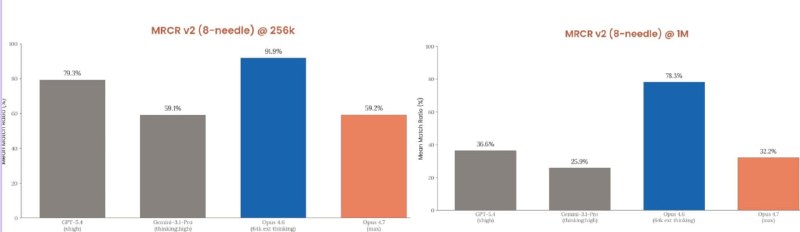
Opus 4.7 серьёзно просел в бенчмарке удержания контекста MRCR v2. Суть теста: в длинный текст прячут 8 фактов, а модель должна все их найти, не перепутать между собой и правильно сослаться
На 256K контекста Opus 4.6 набирал 91,9%, а 4.7 — всего 59,2%. На миллионе токенов разрыв ещё больше: 78,3% у 4.6 против 32,2% у 4.7. Это уже хуже, чем у Gemini 3.1 Pro, у которой все очень плохо с контекстом 😭
Добавить комментарий