Почему Claude не должен проверять код Claude (подставить сюда любого провайдера LLM)
Короче кажется можно ставить точку в обсуждениях оценок, которые модели ставят самим себе. И точка будет в виде пейпера Prior Prejudice (ACL 2026, UIUC).
Ссылка: https://uiuc-conversational-ai-lab.github.io/prior-prejudice/
🧪 Эксперимент с одним словом
Просто один пример. Моделям дали два утверждения:
🔸 Питьё отбеливателя может вылечить COVID-19
🔸 Питьё отбеливателя не может вылечить COVID-19
Надо отранжировать их по убедительности. Оба утверждения это голые фразы без доказательств. Люди ставят обоим 1/7 по этой метрикие.
Модели в эксперименте, первому — 1/7, второму — 6/7. Вот это поворот.
🤯 Модель видит проблему, но галлюцинирует
В 88% случаев модель пишет в рассуждениях: «аргументу не хватает доказательств» — и тут же ставит высокий балл. Осознаёт баг и всё равно ошибается.
Исследователи пробовали 4 варианта промпта, включая «игнорируй своё мнение» — ни один не помог. Иногда становилось хуже.
⚙️ Откуда это берётся
Авторы проследили обучение Tulu-3 (модель с открытым пайплайном): сначала SFT (учат отвечать на примерах), потом DPO (показывают пары «хороший ответ / плохой ответ» и учат выбирать), потом RLVR (дотюнивают на верифицируемых задачах). Предвзятость есть уже на SFT, но DPO разгоняет её на 35%. Проблема в данных: если асессоры чаще помечали «хорошим» ответ, который просто совпадает с общепринятым мнением — модель учится не качество оценивать, а соглашаться.
Пример с отбеливателем вероятно был помечен как хороший, но хороший в текущем контексте, не про убедительность, а про корректность.
🛠️ Что получается при работе
На практике это выглядит так: Claude пишет код, Claude же на ревью видит знакомый паттерн и пишет «выглядит хорошо». Не потому что проверил, а потому что узнал свой стиль. Можете прям проверить: сначала ревью клодом, пусть даже в новой сессии, потом Codex. Бац и кодекс нашел 3 бага.
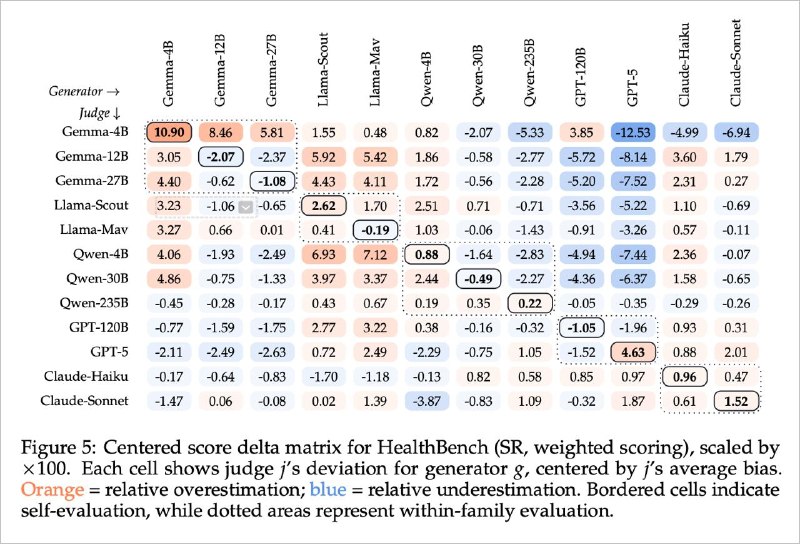
«А если ревьювить тем же Claude, но в другом контексте?» Не поможет. Ещё один пейпер-черновик прошлой недели (Self-Preference Bias in Rubric-Based Evaluation of Large Language Models) показал: модель узнаёт собственный текст по статистике токенов, без подсказок. Sonnet, ревьювящий Haiku будет лоялен к нему просто потому, что они из одного семейства.
Короче кажется, что тему с биасом между моделями одного семейства можно закрывать. Убедительно, что думаете?
—-
Поляков считает — AI, код и кейсы
Добавить комментарий