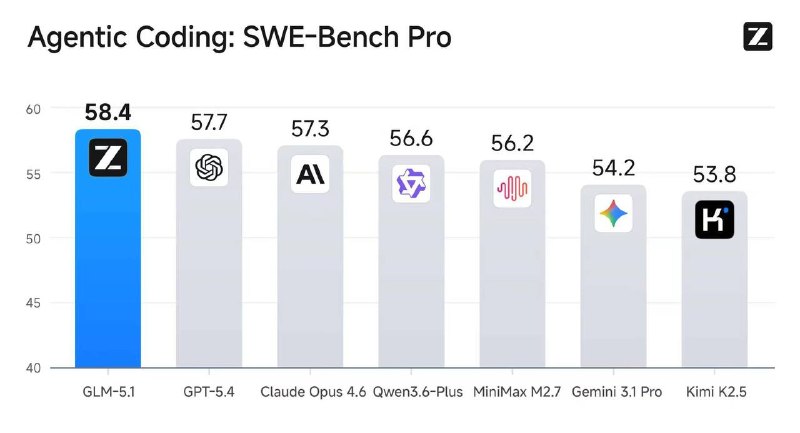
Тем временем, Z.ai выпустили GLM 5.1, которая обошла GPT 5.4 и Opus 4.6 в SWE-Bench Pro (на агентный кодинг)
То что китайцы что-то там обгоняли на SWE-Bench — пофиг, ибо сам бенчмарк был очень посредственным, OpenAI делали про это статью. Но тут обогнали на SWE-Bench Pro, и совсем не могу понять как, ведь бенчмарк этот очень даже показателен
Тут либо GLM 5.1 реально разнос, либо китайцы опять наобучили модель ради хороших бенчмарков. В таком случае больше подобным результатам в SWE-Bench Pro от китайцев верить не будем)) Погнал тестить, кароч 👀
Добавить комментарий